
AI Is Not just about Data – It’s about Context and Governance

Something I keep noticing – across customer calls, conferences, and the occasional brutally honest Slack message from a fellow founder or client, is a version of the same frustration: “We have more data than we know what to do with, and our AI still isn’t working.”
That’s not a compute problem. That’s not a model problem. I’ve heard a version of this exact sentence from at least a dozen teams across different industries. They’ve done the “right” things. I’ve heard this enough times now that it doesn’t surprise me anymore. What does surprise me is that the teams saying it are not small or underfunded. They’ve moved to the cloud. They’re running Spark clusters. They’ve onboarded transformation frameworks. They’re generating more data than ever before. And their AI initiatives are still failing quietly.
Here’s the thing – data volume has never been the point. Not really. The point is whether that data means something, to your systems, in your specific operational context. And whether you’ve earned the right to trust it. That’s data context and governance in AI, and I’d argue it’s the most underrated concept in enterprise AI right now.
What Does “Data with Context and Governance” Actually Mean?
I want to be direct about something before I go further: a lot of vendors have started using “data governance” and “data context” as marketing terms, and it’s made both phrases nearly meaningless. So let me define them the way I actually use them.
Context, in the data sense, is everything that makes a piece of information interpretable. It’s not just a column name – it’s the lineage (where did this number come from?), the semantics (what does “revenue” mean in your org – bookings, recognized, net?), and the ownership (who is accountable when this breaks?). Data without context is like a spreadsheet without column headers. You’ve got numbers. You don’t have information.
Governance is the enforcement layer. It’s access control, yes – but more importantly it’s the system that ensures your data pipelines produce auditable, trustworthy outputs. Governance is what turns a data asset from something you hope is right into something you can bet your compliance posture on.
The definition I disagree with most is the one that treats governance as a checklist – something the legal or compliance team owns, something that slows engineers down. That framing has done real damage. Governance isn’t bureaucracy. Done right, it’s infrastructure. And context isn’t metadata in a catalog that nobody reads. It’s the difference between an AI system that produces insight and one that produces expensive hallucinations.
The State of Data in AI Today
I’ve spent the last several years inside this problem at Vapusdata. When we started talking to enterprises about their data foundations, a pattern emerged immediately: almost everyone was data-rich and signal-poor.
The reasons are consistent. Pipelines get built quickly, under sprint pressure, without lineage tracking. Schemas evolve without versioning. The team that built the original pipeline has three reorgs removed. Data quality checks exist in theory – maybe someone set up a quality validation framework two years ago – but nobody owns the alerts. An observability alert flags an anomaly and it sits in a Slack channel nobody checks.
According to research from Gartner, poor data quality costs organizations an average of $12.9 million per year. That stat has been cited enough that it’s almost become wallpaper. But the more interesting finding, from where I sit, is that organizations typically only discover data quality issues after an AI model has already gone into production and started producing wrong answers. The failure mode is quiet and expensive.
McKinsey’s research on AI value found that companies achieving the most from AI are far more likely to have strong data practices — not just better models. The models are largely a commodity now. The foundation is not.
Over-reliance on tooling is the other trap I see constantly. Engineers pick up Airflow, wire up some orchestration, move data from A to B, and assume the problem is solved. But orchestration is not governance. A pipeline that runs on schedule and produces wrong data reliably is arguably worse than no pipeline at all – it projects confidence where none exists.
Where Context and Governance Change the Game
Context Turns Data into Meaning
Imagine you’re training a model to predict customer churn. Your feature set includes “last login date.” Sounds reasonable. But in one system, “last login” means the customer logged into the web app. In another, it includes API calls from integrations. In a third, it’s populated by a batch job that runs weekly. These are three different signals that look identical to your model.
Without semantic context baked into your data layer, your model is pattern-matching on noise. The model isn’t wrong – it’s doing exactly what it’s supposed to. But the inputs are semantically broken, and no amount of hyperparameter tuning fixes a conceptual mismatch.
This is where ontology becomes relevant – and it’s a word the data industry has either ignored or overcomplicated. In simple terms, a data ontology is a formal definition of the concepts in your domain and how they relate to each other. It answers questions like: what is a “customer” in your system – is it anyone who signed up, anyone who paid, anyone active in the last 90 days? What is the relationship between a “contract” and an “account”? These aren’t technical questions. They’re semantic ones. And without a shared ontology, every team in your organization is essentially speaking a different dialect of the same language. The model has no way to reconcile that. It just picks one interpretation and runs with it – confidently, at scale.
Here having a governed data platform with built-in lineage, semantic documentation, and traceable transformation logic becomes genuinely important — not just a nice-to-have. When every step from source to serving layer is documented and version-controlled, the AI system has access to something more than numbers – it has interpretable signals with documented provenance. This is precisely the kind of foundation Vapusdata is built to provide.
Governance Turns Data into Trust
I used to think of access control as the boring part of governance. I was wrong.
When a model produces a recommendation – a loan decision, a drug interaction flag, a customer segment for a marketing campaign – someone is accountable for that recommendation. In regulated industries, that accountability is legal and documented. In any industry, when the model is wrong, someone takes the call.
Governance is what makes that accountability traceable. Who had access to this training data? When was it last validated? What schema version is the model operating on? These aren’t philosophical questions. They’re production questions that come up in the worst moments — audits, incidents, regulatory reviews.
The EU AI Act and similar frameworks are making this non-optional for many organizations. But I’d argue that even absent regulation, governed data pipelines are a competitive advantage. They let you move faster, not slower – because you spend less time debugging mystery incidents after they’ve already caused damage.
AI Systems Need Both – Not One
Context without governance is chaos. I’ve seen it: a beautifully documented semantic layer, rich lineage, detailed ownership – and then an intern runs a raw SQL query against production, bypasses all of it, and corrupts a training set nobody notices for three weeks.
Governance without context is rigid. You’ve locked everything down, access matrices everywhere, every table has an owner – but nobody has defined what “active user” means, so every team uses a different definition and your cross-functional dashboards are fundamentally lying to leadership.
You need both. They’re not optional extensions of each other. They’re two sides of the same foundation.

Traditional Data Approach vs. Context & Governance driven Approach
Here’s what I used to see when I entered a new data environment: a massive data lake with petabytes of raw data, no clear ownership, schemas that had evolved organically over years, and a team of engineers spending 60–70% of their time debugging pipeline failures rather than building anything new. An MIT Sloan study found that data scientists spend roughly 80% of their time on data preparation rather than actual analysis. I don’t find that number surprising at all.
Here’s what we do differently now at Vapusdata, and what I’d advocate for in any serious data organization:
The shift is from data lakes to data products – bounded, owned, versioned, tested datasets that behave like software artifacts. They have SLAs. They have documented schemas. They have quality contracts. When something breaks, there’s a clear escalation path.
The shift is from pipelines to governed ecosystems – where lineage is first-class, access is policy-driven, and every transformation step is auditable. It’s not slower. It’s actually faster at scale because you stop paying the compounding cost of trust debt.
The Problems This Actually Solves
Let me make this concrete, because “context and governance” can sound abstract until you’ve seen the failure modes up close.
AI hallucinations from poor data grounding. Large language models operating on enterprise data – retrieval-augmented systems, copilots, internal search tools – will hallucinate with far more confidence when the underlying data is inconsistent or poorly labeled. The model doesn’t know that your “Q3 revenue” column has three different definitions depending on the business unit. It just finds the closest match and answers with full confidence. Context-rich data dramatically reduces this class of failure.
Broken dashboards and metric inconsistency. I’ve sat in executive reviews where two dashboards showed different numbers for the same KPI. Both were “correct” — they were just pulling from different tables with different transformation logic. This is a governance failure, and it destroys AI credibility long before the AI system itself has done anything wrong.
Compliance risk in enterprise AI. I came across a remarkable story recently that illustrates this from an unexpected angle. Paul Conyngham, an Australian AI and data entrepreneur, used AI tools – ChatGPT for research planning, AlphaFold for protein structure modeling, and his own machine learning algorithms – to design a personalized mRNA cancer vaccine for his dog Rosie, who had been given months to live with aggressive mast cell cancer. Working with researchers at the University of New South Wales, he spent $3,000 to sequence Rosie’s tumor DNA, then used AI to identify the mutations driving her cancer and design a targeted vaccine. The tumor on her leg shrank by roughly 75%.
It’s a genuinely incredible story. But here’s what stood out to me as someone who thinks about data systems: Conyngham described the red tape as harder than the vaccine creation itself — a 100-page ethics document that took three months of two-hour nightly sessions to complete. The AI worked. The data pipeline worked. But the governance layer – who has access, under what approval, with what oversight – was the actual hard problem.
The AI did not do this alone. It acted as a guide and assistant, but qualified scientists still had to check its work and do the hard parts in the lab. That’s precisely the right framing for enterprise AI too. Models are accelerants. The context and governance structure around them is what determines whether the acceleration is safe and directed or chaotic and destructive.
How to Get Started — What I’d Do If I Were You
If I were walking into a new organization tomorrow tasked with making AI actually work, I wouldn’t start with models. I’d start here:
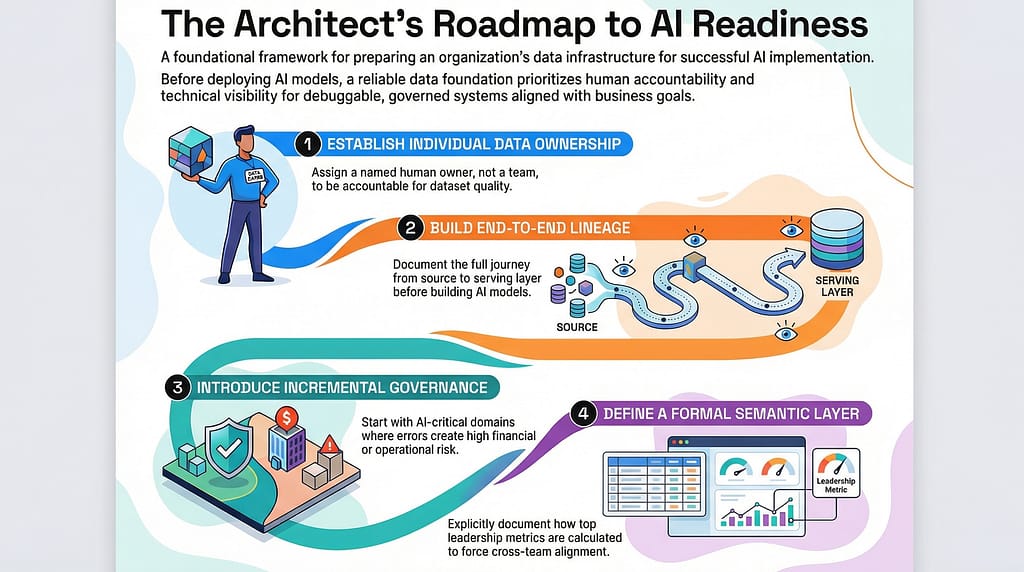
First: Establish data ownership. Every significant dataset needs a named human owner who is accountable for its quality and definition. Not a team. A person. This is the single highest-leverage change most organizations can make.
Second: Build lineage before you build anything else. Make the full journey from data source to serving layer visible, documented, and maintained. You cannot debug what you cannot trace. A platform that keeps lineage as a first-class concern – rather than bolting it on later – pays for itself the first time something breaks in production.
Third: Introduce governance incrementally, not all at once. Don’t try to govern everything. Pick your most AI-critical data domains first — the ones where wrong answers cost real money or create real risk — and build your governance muscles there. Expand once you have patterns that work.
Fourth: Define your semantic layer explicitly. Pick three metrics that matter to your leadership team and write down, formally, exactly how they’re calculated. Force alignment across teams. This alone will surface more hidden data problems than any automated tool.
What I’ve Learned the Hard Way
Before starting Vapusdata, I spent years inside enterprise software – working close to large, well-resourced infrastructure teams. And the thing that struck me, again and again, was how little the quality of the tooling correlated with the quality of the decisions being made.
These were not small companies. They had serious engineering talent and real budgets. But the data flowing through their systems was owned by no one, defined inconsistently across teams, and trusted mostly by habit rather than by evidence. When AI started entering the conversation, those pre-existing cracks didn’t stay hidden – they widened fast.
What I didn’t expect was how much that pattern repeated itself everywhere I looked. It wasn’t a legacy company problem or a scale problem. Teams would arrive with the latest tooling, genuinely excited, and still hit the same wall – because they’d invested in moving data before they’d invested in understanding it.
That frustration is a large part of why Vapusdata exists. We built it specifically to address this gap – not another orchestration layer, not another dashboard tool, but a platform that treats context and governance as first-class concerns from day one. The idea was simple: if the foundational problems keep showing up in the same shape across organizations, build something that attacks those foundations directly rather than adding more tooling on top of a broken base.
The lesson I carry from all of it: no tool saves you from a culture that treats data as infrastructure rather than as a product. The stack is not the strategy. I’ve seen teams with modest tooling and strong data ownership consistently outperform teams with world-class infrastructure and no accountability model. Every single time.
Where This Is All Heading
I could be wrong, but here’s what I think: the next inflection point in enterprise AI is not a better model. It’s a better data paradigm.
We’ve been through the model-centric era – “get the best model, that’s the product.” We’re moving through data-centric AI now – “the quality of your data matters as much as your architecture.” I think the next shift is context-centric AI, where the competitive advantage is not what data you have, or even how clean it is, but how richly annotated, semantically grounded, and governed that data is as it flows into your systems.
Governance will become a moat. Organizations that treat it as a cost center are making a strategic mistake. The ones that build governed data ecosystems now will move faster in the AI era – not slower – because they won’t be constantly putting out the fires that ungoverned data generates.
The counterintuitive truth that I keep coming back to: more data often makes AI worse, not better. Adding noisy, uncontextualized data to a training set or retrieval system doesn’t improve the model – it increases the signal-to-noise problem. Less data, better governed, more richly contextualized, is almost always the right direction.
FAQs
Data context is everything that makes raw data interpretable – lineage (where it came from), semantics (what it actually means in your specific domain), and ownership (who is accountable for its accuracy).
An AI system without access to contextual data is essentially doing sophisticated pattern matching on signals it can’t actually understand. It produces outputs. It doesn’t produce insight.
2. Is more data always better for AI?
No, and this is probably the most dangerous assumption in AI right now. More data increases the surface area for inconsistency, noise, and semantic ambiguity.
I’ve seen organizations dump unfiltered data into retrieval systems and watch AI accuracy decrease. The question is never “how much data do we have” – it’s “how much of this data is signal, in context, that a model can actually learn from.”
3. How does governance improve AI outcomes?
Governance creates trust. When your data pipeline is auditable – when you know who touched what, when the schema last changed, what quality checks it passed – your model’s outputs become traceable and defensible.
This matters operationally (faster debugging), commercially (stakeholder confidence), and legally (compliance). Ungoverned AI might produce right answers sometimes. Governed AI produces auditable answers consistently.
4. Can small teams implement data governance?
Yes, and they should start simpler than they think necessary. Governance at a five-person startup looks like: one person owns each data domain, all transformation logic lives in version control, and you’ve written down what your three most important metrics mean.
That’s it. You scale the formality with the stakes. The discipline of ownership and lineage is what matters — the tooling can catch up.
5. What’s the biggest mistake companies make with AI data strategy?
Investing in AI before investing in data foundations. I’ve seen companies spend seven figures on model infrastructure and ML platforms while their underlying data is ungoverned, undocumented, and semantically inconsistent.
The model is not the bottleneck. It has never been the bottleneck. Fix the foundation first, and the models get dramatically better without touching them.


