
Principles of VapusData Containers (VDC)

Sharing data across teams shouldn’t feel risky. However, in most companies, data lives in too many tools, clouds, and domain systems. As a result, teams spend more time hunting for the “right” dataset and getting approvals than actually building.
VapusData changes that. We help organizations share data products securely, with clear ownership and built-in governance. Our mission is to make data more secure and shareable across the organization. We are focused on simplifying the experience of a data environment that is both complicated and dispersed, as well as providing a governed platform to securely build and share the data products
One such important aspect of the VapusData Ecosystem is VDc, i.e., VapusData Containers. Here we will talk about the basic amendments to VDc and how they are going to change the way data is managed from a centralized model to a decentralized one.
Before we dive in: what is VDc?
To understand the VDc amendments, we first need a simple definition of VDc and its core component, Nabhik.
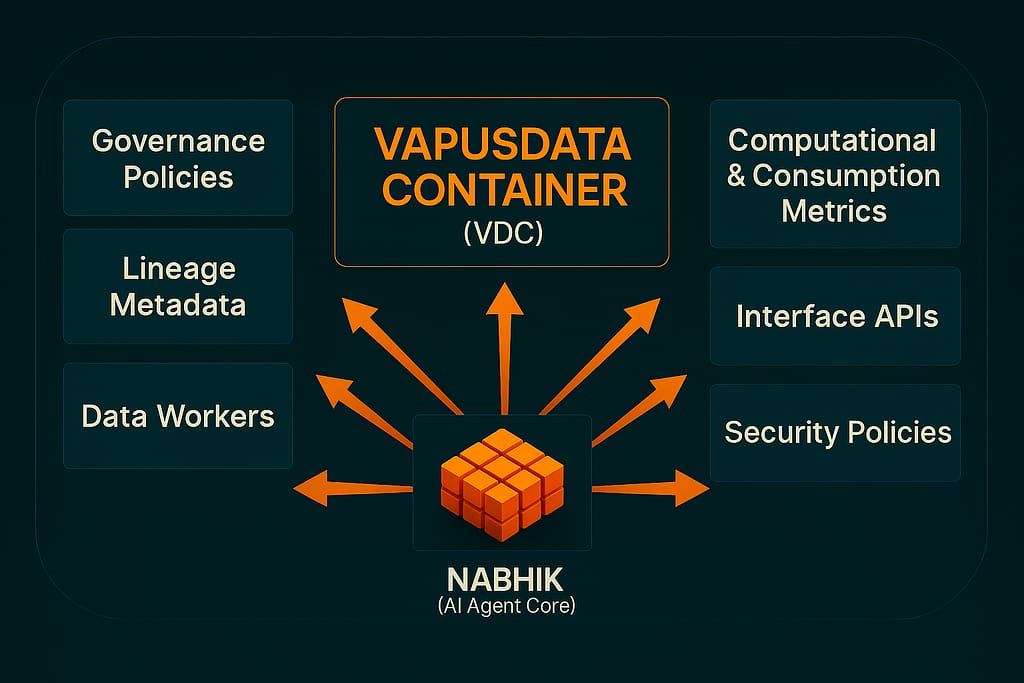
VDc
Vapus Data Containers (VDc) are autonomous software units that package a data product end-to-end. Domain teams build and manage them independently. Each VDc can include:
- Data workers
- Governance policies
- Security policies and tools
- Interface APIs
- Lineage and metadata
VDc uses a standard interface. Because of this, teams can access a data product securely. They do so without relying on the owner’s internal domain system. At the same time, the owner domain still controls access through its policies and compliance rules. Therefore, domains can collaborate more easily while the organization keeps security and consistency intact.
Nabhik: The Core of VDc
At the center of VDc is Nabhik, the component that coordinates data workers and manages the data product lifecycle.
First, Nabhik orchestrates data extraction and transformation while preserving lineage. Next, it supports AI agent operations, so teams can bring AI into the flow without stitching together extra systems. Finally, it tracks the data product from creation to retirement, which improves reliability and auditability across the lifecycle.
Now, let’s get into the fun part: the VDc amendments.
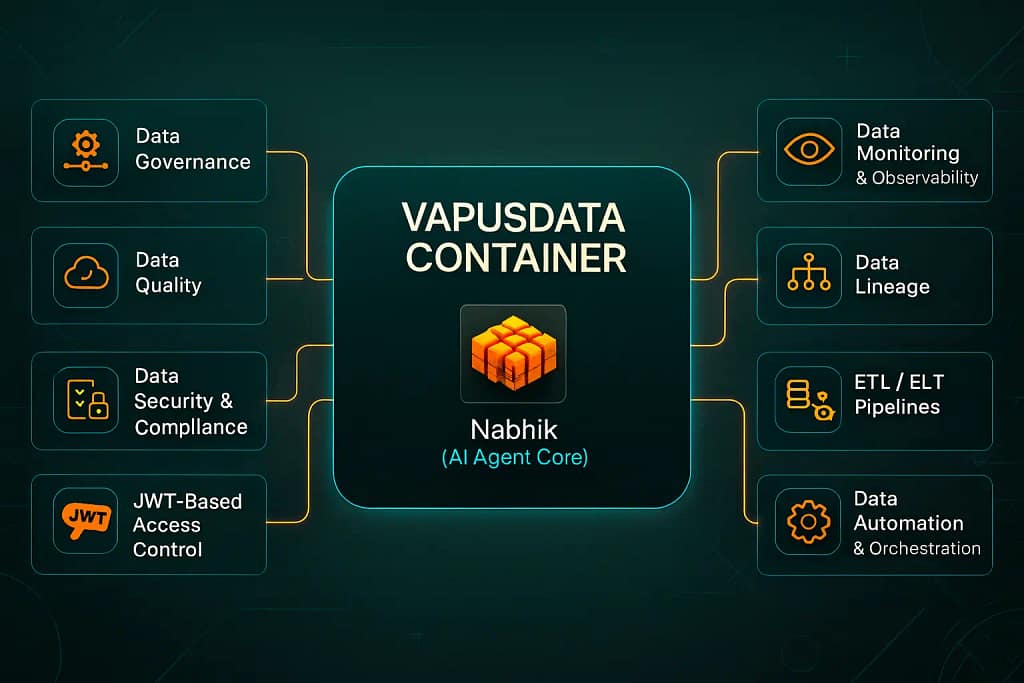
VDc amendments
Governance
Traditional data platforms often make governance harder than it should be. Data usually gets created in domain-specific environments, yet a central team manages access, policies, and metadata. Unfortunately, that central team rarely has full context on domain rules. As a result, governance becomes slow, inconsistent, and frustrating.
VDc changes that. It provides a built-in governance framework that lets domain teams define policies and procedures while still aligning with organizational standards. Consequently, teams can ship data products that stay accessible, secure, consistent, and compliant.
Here are the key governance areas in VDc.
Compliance
VDc enforces compliance with relevant data protection regulations. That way, teams can meet legal and ethical requirements as part of daily operations, not as a separate cleanup step.
Access Control
VDc includes mutable but attested access-control policies for eligible users. When someone accesses a data product, VDc enforces domain authentication and authorization requirements.
In addition, access policies are versioned inside the VDc. So, when a policy changes, the domain ships a new VDc version. This makes access changes explicit and traceable.
Attestation
Version control causes real trust issues in most data-product practices. People often consume “the same” dataset without knowing what changed, who approved it, or whether the pipeline followed the right process.
VDc solves this by requiring domain owners to version and attest a VDc before they publish it for discovery and consumption.
VDc attestation can include:
- VDc signing information
- Build platform details
- Rootfs digests
- Digests for the data product and policies
- Digests for the build-and-publish lineage
As a result, consumers can trust what they use, and platform teams can audit the trail end-to-end.
Standardization
Teams struggle to standardize data product delivery because they work with many sources, tools, and language drivers. Therefore, building one strict, universal framework rarely works.
VDc takes a more practical approach. It lets domain owners reuse standard data workers provided by the VapusData platform. These workers package common workflows in containers, which helps teams ship faster and more consistently.
Common VDc data workers include:
- ETL data worker
- Virtual data worker
- Streaming data worker
- Replication data worker
- CDC data worker
Accessibility
Even if engineers build a great data product, they still face the same question: how do users find it, understand it, and access it safely?
VDc addresses this through consistent metadata ingestion and search. It uses a uniform system to ingest metadata into FTS and semantic search. Then the VapusData platform collects signals, converts them into structured text, and indexes them for discovery.
VDc can index:
- Data lineage
- Data schemas
- Data domain information
- Data worker logs
For access, VDc uses a secure channel for both authentication and authorization. Additionally, the platform encrypts keys and related configuration inside the container, and ships them as part of the same unit. As a result, teams avoid risky side channels for secrets and access setup.
Security
Security matters inside a domain, and it matters even more when data moves outside the domain. Teams often worry about credential leakage, log leakage, secret rotation, and inconsistent enforcement.
VDc builds security into the data product lifecycle from the start. It enforces encryption and policy controls on every shipment of a data product version. Therefore, teams can share data without weakening their security posture.
Key security capabilities in VDc include:
- Domain-owned, domain-specific asymmetric encryption for secrets and configuration
- Salt-based hashing for input and output parameters
- Independent authentication policies for every VDc
- Interface-level access that exposes only relevant data
FAQs
VDc (Vapus Data Containers) are portable, autonomous software units that package a data product end-to-end. Each VDc bundles the data workers, governance and security policies, APIs, and lineage/metadata required to build, ship, and operate a data product consistently across domains.
2. How does VDc enable secure data sharing across domains in an organization?
VDc enables secure sharing by using a standard access interface while still enforcing the owner domain’s authentication, authorization, and compliance policies. In addition, VDc ships policies and controls with the data product, so access stays governed even when data moves outside the domain boundary.
3. How is VDc different from a traditional centralized data platform or central data team model?
Traditional models often centralize control with a data team that may not fully understand domain context, which creates bottlenecks and inconsistent policies. VDc shifts ownership to domain teams while keeping governance standardized, so domains can move faster and share safely without waiting on a central gatekeeper for every change.
4. What is Nabhik, and what role does it play inside VDc?
Nabhik is the core component inside VDc that orchestrates data workers and manages the data product lifecycle. It coordinates extraction and transformation while preserving lineage, supports AI agent operations in the same flow, and tracks each product from creation through retirement for better reliability and auditability.





