
What is a Data Pipeline?

A data pipeline consists of structured processes. It moves data from one system to another. It usually transfers data from multiple sources to a data warehouse, data lake, or analytics platform. Along the way, it can clean the data. It can transform and enrich it. It can also validate the data to ensure it is ready for analysis, reporting, or powering AI applications.
“Think of a data pipeline as a well planned railway system. Raw data is like cargo loaded at different stations. The pipeline is the track network that ensures the cargo reaches the right destination efficiently and without loss. Each station along the way can modify, sort, or repackage the cargo, just as pipeline components process and structure data.”
Unlike one time data migrations, pipelines are automated and repeatable. They run continuously or on a schedule, ensuring data flows seamlessly whether in real time or in batch. This reliability is crucial for modern businesses that depend on up to date insights, machine learning models, and regulatory reporting.
In modern architectures, pipelines do not just move data. They observe, monitor, and govern it. Features like lineage tracking, schema evolution, and data quality checks are built into well designed pipelines. These capabilities ensure data remains accurate, compliant, and traceable even as volumes grow across hybrid or multi cloud environments.
Types of Data Pipelines:
Not all data pipelines serve the same purpose. Depending on the use case, data volume, and processing needs, different types of pipelines are used. Broadly, they can be grouped into four key categories.
1. Batch Data Pipelines
Batch pipelines collect and process data in groups at scheduled intervals. For example, a retail company might run a nightly job that moves the day’s transactions into a data warehouse for reporting. Batch processing works well when real time insights are not critical and when data volumes are large.
2. Real Time or Streaming Data Pipelines
Streaming pipelines continuously capture and process data the moment it is generated. This approach is ideal for applications that rely on instant insights, such as fraud detection, recommendation engines, or IoT monitoring. Streaming pipelines focus on low latency and high availability to keep information fresh.
3. Cloud Data Pipelines
Cloud pipelines leverage managed services and modern data platforms to handle data movement and transformation at scale. These pipelines are popular for their flexibility, cost efficiency, and ability to integrate with multiple tools and storage layers across different cloud providers.
4. Change Data Capture or CDC Pipelines
CDC pipelines detect and replicate only the changes made to a source system, instead of moving entire datasets each time. This makes them highly efficient for scenarios that require near real time synchronization between transactional systems and analytical platforms. CDC is a key approach in zero ETL strategies where minimal transformation is applied during movement.
Modern data teams often combine these types to build hybrid pipelines. For example, a company might use batch pipelines for historical reporting while streaming pipelines power dashboards that track live business metrics.

What are the Benefits of a Data Pipeline?
A well built data pipeline is more than just a way to move information. It is a foundation that supports reliable decision making, smooth operations, and scalable innovation. Here are the key benefits:
1. Consistent and Reliable Data Flow
A data pipeline ensures that data moves from source to destination in a controlled and repeatable manner. It eliminates manual processes and reduces the chances of delays or human error. This consistent flow of data allows teams to trust the information they work with.
2. Faster Access to Insights
Automated pipelines allow organizations to process and deliver data in real time or at regular intervals. Instead of waiting for manual updates, analysts, data scientists, and business teams get fresh data when they need it. This leads to faster reporting, more timely decisions, and improved responsiveness.
3. Scalability as Data Grows
As data volumes increase, pipelines make it easy to scale without overhauling existing systems. Modern architectures support parallel processing, cloud based storage, and distributed computing, ensuring the pipeline can handle larger workloads without compromising performance.
4. Better Data Quality and Governance
Pipelines include steps to validate, clean, and enrich data automatically. Features like schema checks, lineage tracking, and data quality rules help maintain accuracy and compliance with regulations such as GDPR or HIPAA. This makes pipelines critical for secure and governed data operations.
5. Cost and Resource Efficiency
By automating ingestion, transformation, and monitoring, pipelines reduce the need for manual intervention and minimize operational overhead. Organizations save both time and infrastructure costs while maintaining a high level of reliability.
6. Foundation for Advanced Analytics and AI
A clean and well structured flow of data is essential for machine learning models, real time dashboards, and advanced analytics. Pipelines provide the dependable infrastructure required to support AI applications and enable faster experimentation and deployment.
Difference between Data Pipelines and ETL Pipelines
The terms data pipeline and ETL pipeline are often used interchangeably, but they are not the same. Understanding the difference is essential for designing the right architecture for your data operations.

Data Pipelines
A data pipeline is a broader concept. It refers to any automated system that moves data from one place to another, whether it involves transformation or not. Data pipelines can handle a variety of workflows including ingestion, movement, monitoring, quality checks, and routing data to different destinations such as data warehouses, data lakes, operational systems, or AI platforms.
Data pipelines may include ETL processes, ELT processes, streaming pipelines, or even simple replication tasks. Their main focus is on ensuring data flow, reliability, and governance across the entire data ecosystem.
ETL Pipelines
An ETL pipeline is a specific type of data pipeline that focuses on three key steps: Extract, Transform, and Load.
- Extract pulls data from various source systems.
- Transform cleans, enriches, and reshapes data to match the target schema or business rules.
- Load pushes the transformed data into a target system such as a data warehouse.
ETL pipelines are mainly used for batch processing and structured transformations that prepare data for analytics and reporting. While they are an important part of many data strategies, ETL pipelines are only one piece of the larger data pipeline landscape.
Every ETL pipeline is a data pipeline, but not every data pipeline is an ETL pipeline. Data pipelines can support real time streaming, CDC, ELT, or direct transfers without complex transformations. ETL focuses on structured data preparation, while data pipelines provide the end to end infrastructure that connects all parts of the data ecosystem.
Data Pipeline Architecture
A well designed data pipeline architecture defines how data flows from sources to destinations in a reliable, scalable, and secure way. It ensures smooth movement, transformation, monitoring, and delivery of data for analytics and AI.
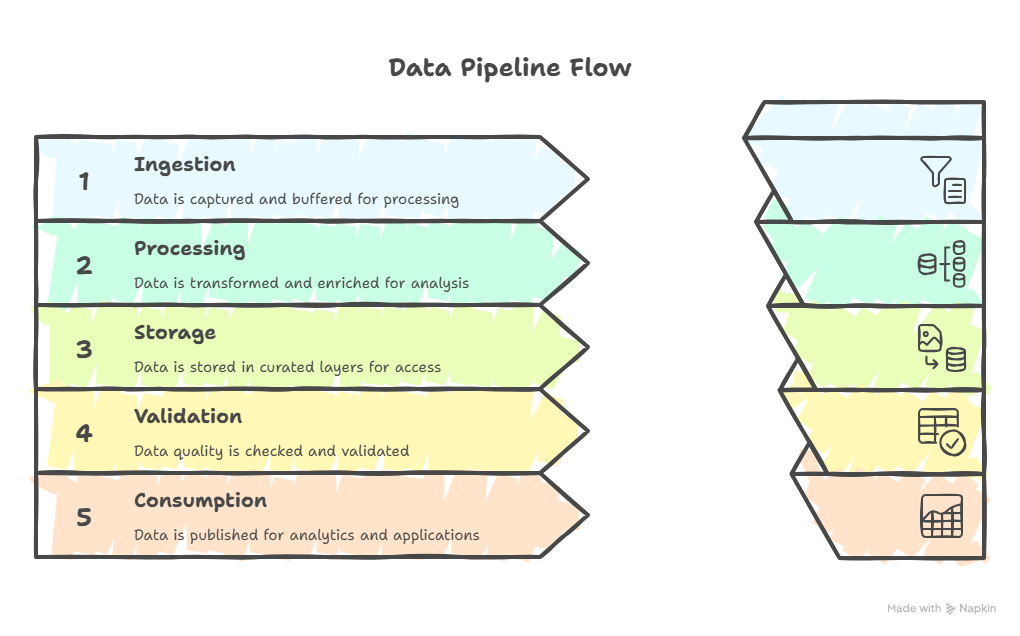
Core Components
- Data Sources
Applications, databases, files, APIs, and event streams where raw data originates. - Ingestion Layer
Collects and brings data into the system through batch jobs or streaming connectors. - Storage Layer
Stores data in raw and curated zones using data lakes, warehouses, or data lakehouses. - Processing Layer
Transforms and enriches data using ETL, ELT, or real time streaming jobs. - Orchestration and Monitoring
Coordinates workflows, manages dependencies, tracks performance, and raises alerts. - Security and Governance
Enforces access control, compliance, lineage, and quality rules to ensure trustworthy data. - Consumption Layer
Serves clean data to BI dashboards, analytics tools, machine learning pipelines, and applications.
Common Patterns
- Batch architecture for scheduled large scale processing.
- Streaming architecture for real time insights.
- Lambda or Kappa models to combine batch accuracy with streaming speed.
This layered approach gives teams reliability, scalability, and flexibility, making data pipelines the backbone of modern analytics and AI systems.
Future of Data Pipelines: AI
The future of data pipelines is being reshaped by AI driven automation. Traditional pipelines require constant manual setup, monitoring, and maintenance. AI is transforming them into autonomous, adaptive, and intelligent systems that can handle complexity at scale.
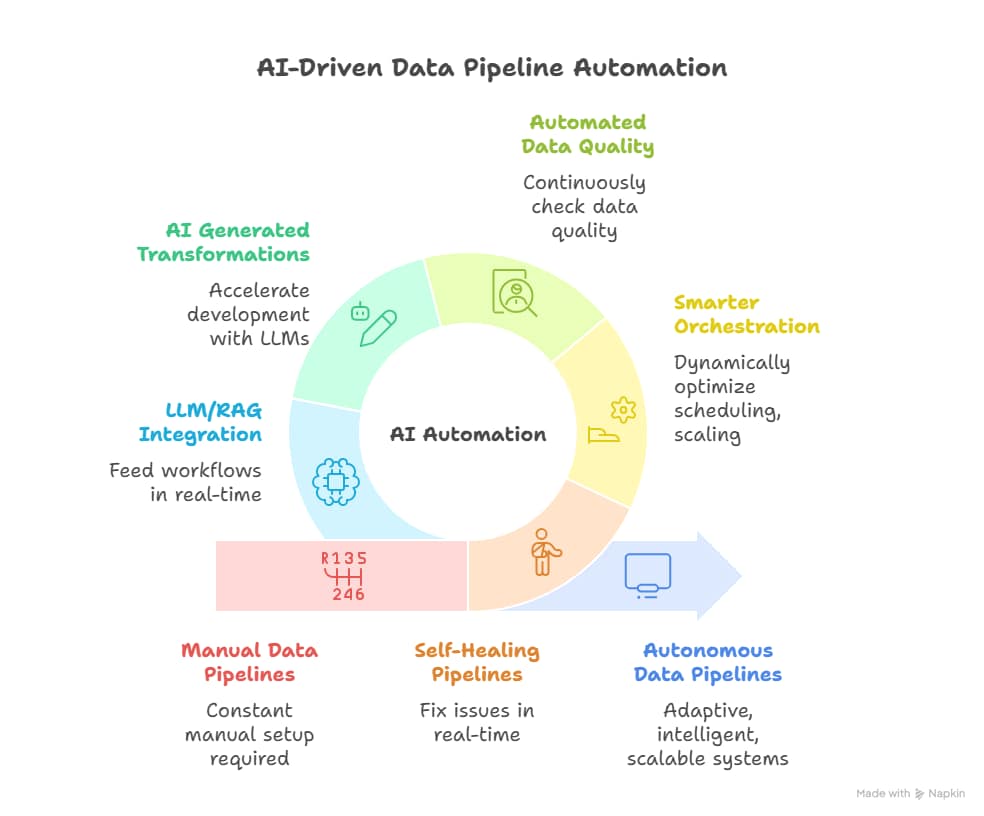
Key Shifts
- Self healing Pipelines
AI powered pipelines can detect anomalies, predict failures, and fix issues in real time without manual intervention. This reduces downtime and improves reliability. - Smarter orchestration
Machine learning dynamically optimized scheduling, scaling, and resource allocation, ensuring faster processing and lower operational costs. - Automated data quality
Models continuously check data quality, track lineage, and adapt to schema changes. Pipelines learn from past issues and strengthen themselves over time. - AI generated transformations
Large language models can generate queries, mappings, and transformation logic based on business rules, accelerating development. - Integration with LLM and RAG architectures
Future pipelines will not only serve analytics but also feed retrieval augmented generation workflows and model fine tuning in real time.
This evolution creates a clear need for platforms that combine pipeline reliability with AI driven intelligence and built in governance. That is exactly where VapusData steps in.
How VapusData Helps
VapusData is designed for this new era. It brings together data pipelines, AI, and governance into a single decentralized operating system. Instead of stitching multiple tools together, teams get a unified platform that automates, optimizes, and secures data operations end to end.
Key Capabilities
- Agent driven DataOps
VapusData uses intelligent agents that monitor, learn, and adapt to pipeline behavior. They predict bottlenecks, auto resolve issues, and keep pipelines healthy without human intervention. - Full stack observability
Every stage is tracked with lineage, real time quality checks, and policy enforcement, ensuring complete visibility. - No code compliance and governance
Regulations like GDPR, HIPAA, and CCPA are built into the platform by design, ensuring data security and audit readiness at every layer. - Scalable and cost efficient
VapusData’s decentralized architecture and AI powered optimization deliver faster workflows and significantly lower AI and ML infrastructure costs. - Seamless integration
It connects effortlessly with major clouds, warehouses, and AI tools to build batch, streaming, or zero ETL pipelines.
By blending AI intelligence, observability, and governance, VapusData turns traditional pipelines into autonomous data ecosystems that power analytics, machine learning, and decision making in real time.
As data volumes grow and real time intelligence becomes essential, data pipelines sit at the core of every modern enterprise. AI is redefining how these pipelines are built, monitored, and optimized, shifting from manual maintenance to intelligent automation.
VapusData brings this vision to life with a platform that unifies AI, observability, and governance. It helps teams build reliable, scalable, and future ready pipelines that power smarter decisions and unlock new possibilities.




